CEDAR: Critical Editions for Digital Analysis and Research
Critical Editions for Digital Analysis and Research (CEDAR) is a multi-project digital humanities initiative at the University of Chicago dedicated to creating new digital tools for text-critical research. CEDAR is built in the Online Cultural and Historical Research Environment (OCHRE), an XML graph database based at the University of Chicago and situated in the Humanities Division’s new Center for Digital Studies. One of CEDAR’s lead projects treats the Hebrew Bible. It is led by Jeffrey Stackert and Simeon Chavel of the Divinity School and Ron Hendel of the University of California, Berkeley. The other lead project, led by Ellen MacKay of the Department of English, treats Shakespeare’s The Taming of the Shrew. CEDAR also includes projects on Sumerian and Akkadian Gilgamesh and the works of Herman Melville, and it is developing new collaborations with scholars on campus and around the world.
The tools offered by CEDAR, made possible by a new approach to encoding texts, represent a significant development in the history of textual criticism. There have been almost no conceptual advances in the tools for studying the differences between multiple versions of a text since the task was first undertaken in the Great Library of Alexandria before the Common Era. Word processors have made publishing easier, and digital imaging techniques can produce clearer and more detailed photographs of manuscripts, but for the most part scholars have continued to work with flat, static text and images.
CEDAR implements a new approach to encoding text that might be called the database model (see David Schloen and Sandra Schloen, “Beyond Gutenberg: Transcending the Document Paradigm in Digital Humanities,” DHQ 8 [2014]). In the CEDAR project, although we are creating tools to represent and study texts, there are no “texts” per se stored in the database. That is to say, the database does not store linear strings of characters comprising whole compositions. Instead, each line, each word, each character, and even each diacritical mark is stored as its own discrete XML file. This organization creates a distinction between how the user reads the data and how the data is organized in the database.
Such a distinction is not maintained in the dominant approach to encoding texts in the humanities, which might be called the document model. The document model both displays and organizes data in the same structure as physical documents, where characters are assigned a fixed position in one or two dimensions. This model fails to expand the kinds of research questions scholars can ask because it reproduces the design of print media.
The database model is especially powerful for textual criticism because the same database items are reused in different realizations of the same text. Combinations of these items are assigned to hierarchies that represent individual manuscripts. When the user asks to view the various manuscripts of, say, the biblical book of Genesis, the software generates them by gathering and arranging the same underlying database items according to each manuscript’s hierarchies. The user sees separate texts, but within the database, each “text” is simply a recombination of the same building blocks. This structure means that instead of existing in one or two dimensions, as in the document model, texts in the database model exist as if in three dimensions. They can then, for example, be stacked one on top of the other, becoming like transparency sheets—a process that greatly facilitates comparison. The software employs visual cues (currently color-coding) to indicate where manuscripts agree and where they differ. Clicking on a character calls up information about alternative readings and where they are found.
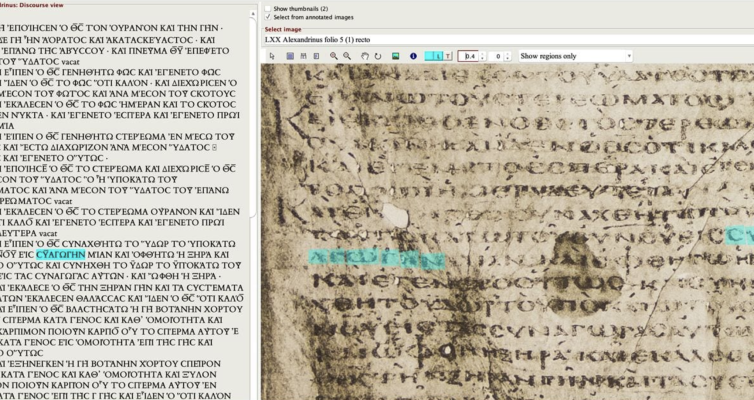
CEDAR also integrates transcriptions of manuscripts with images of the manuscripts themselves. After a digital image is added to the database, we can demarcate areas of the image to link to specific characters or words in the transcription. When a user clicks on the transcription, the linked character on the image is highlighted. Clicking on the image also highlights the linked character in the transcription. This feature, called “hot-spotting,” is particularly useful for studying fragmentary or damaged manuscripts in which reconstructions may be uncertain, for it allows a scholar to communicate precisely which character traces are being interpreted. Furthermore, after a manuscript has been hot-spotted, a user can query the database for all images of a given character. This visual catalog serves as a script chart for evaluating broken characters, a feature that greatly improves the precision of paleographical research and textual reconstruction.
CEDAR is an exciting advance in text-critical research that ultimately seeks a more democratic and critical engagement with both religious and other texts. It is also a valuable training opportunity for the students who are actively working on the project, both with respect to text-critical study and digital humanities research.
More information about the CEDAR Initiative can be found at https://cedar.uchicago.edu/ and at https://tinyurl.com/tsmy89f3.